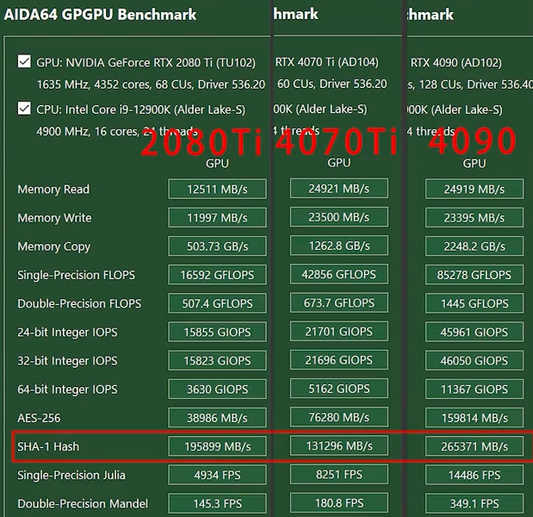
With the rapid advancement of AI, running large language models (LLMs) like DeepSeek locally has become a game-changer for developers and enterprises. However, hardware limitations often pose challenges. In this guide, we’ll walk through how to deploy DeepSeek models on NVIDIA 2080Ti GPUs upgraded to 22GB VRAM—a cost-effective solution for powerful local inference
Upgraded 2080Ti GPUs offer a budget-friendly path to local AI deployment. Whether you choose vLLM for speed or Ollama for quantized models, this setup unlocks powerful capabilities without relying on cloud services. For detailed steps, refer to ModelScope and GeekyShu’s benchmarks.